Introduction to Machine Learning
These are my attempts to write a series of slides on the many topic of ML.
- Introduction slides
- Why Learning?
- The Basic Ideas of Learning slides
- Some of the basic ideas on Learning
- Linear Models slides
- A basic introduction to Linear models
- Some Basic ideas on regularization
- Interludes with Linear Algebra and Calculus
- Regularization slides
- A deeper study in the field of regularization
- Batch and Stochastic Gradient Descent slides
- Batch Gradient Descent
- Accelerating Gradient Descent
- Stochastic Gradient Descent
- Minbatch
- Regret in Machine Learning
- AdaGrad
- ADAM
- Logistic Regression slides
- Interlude with Generative vs Discriminative models
- The Logistic Regression model
- Accelerating the logistic regression
- Introduction to Bayes Classification slides
- Naive Bayes
- Discriminative Functions
- Maximum a Posteriori Methods
- Going beyond Maximum Likelihood
- The General Case
- How can be used in Bayesian Learning?
- EM Algorithm slides
- A classic example of the use of the MAP
- Its use in clustering
- Feature Selection slides
- Introduction to the curse of dimensionality
- Normalization the classic methods
- Data imputation using EM and Matrix Completion
- Methods for Subset Selection
- Shrinkage methods, the classic LASSO
- Feature Generation slides
- Introduction
- Fisher Linear Discriminant
- Principal Component Analysis
- Singular Value Decomposition
- Measures of Accuracy slides
- The alpha beta errors
- The Confusion Matrix
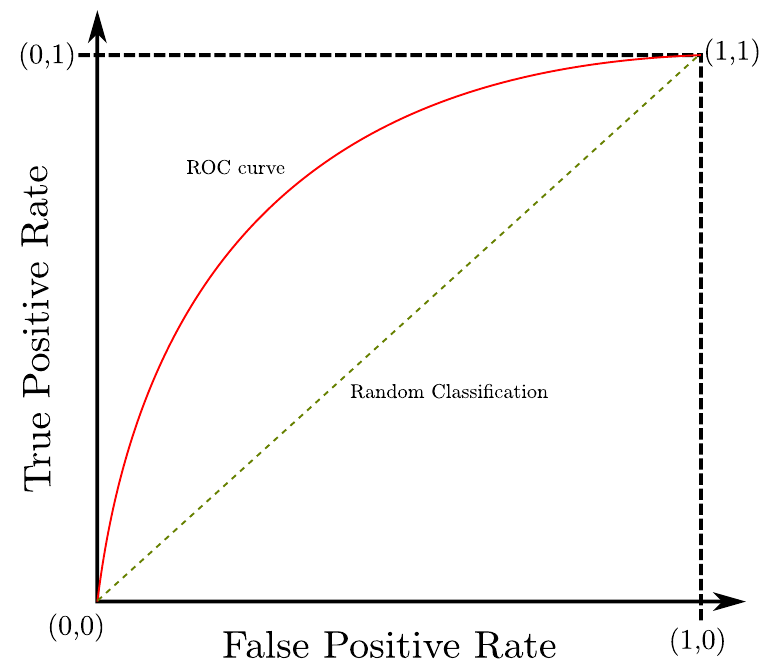
- The ROC curve
- Hidden Markov Models slides
- Another classic example of the use of Dynamic Programming and EM
- The Three Problems
- Support Vector Machines slides
- The idea of margins
- Using the dual solution
- The kernel trick
- The soft margins
- The Perceptron slides
- The first discrete neural network
- The Idea of Learning
- Multilayer Perceptron slides
- The Xor Problem
- The Hidden Layer
- Backpropagation for the new architecture
- Heuristic to improve the performance
- The Universal Representation Theorem slides
- Cybenko Theorem
- Convolutional Networks slides
- Introduction to the image locality problem
- How convolutions can solve this problems
- Backpropagation on the CNN
- Regression and Classification Trees slides
- Using decision trees for Regression
- The Classification Tree
- Entropy to build the Classification Tree
- Vapnik-Chervonenkis Dimensions slides
- Can we learn?
- The Shattering of the space
- The Inequality
- How to measure the power of a classifier
- Combining Models and Boosting slides
- Bagging
- Mixture of Experts
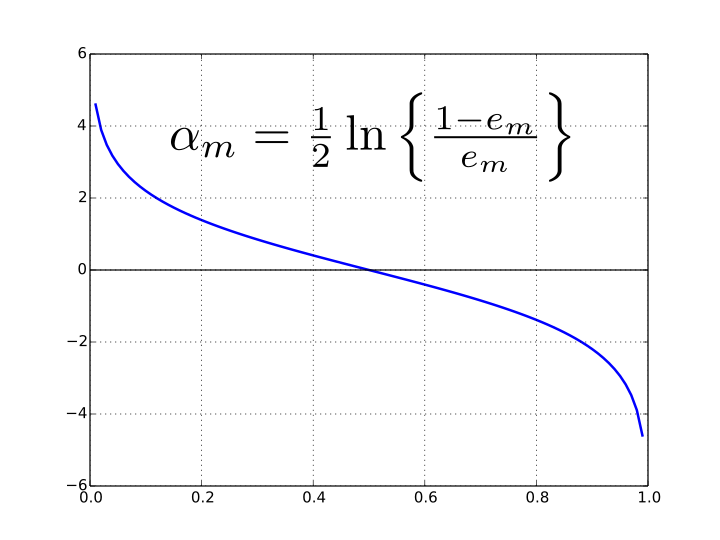
- AdaBoosting
- Boosting Trees, XBoost and Random Forrest slides
- Using Boosting in Trees
- Random Forrest
- Taylor approximation for Boosting Trees
- Introduction to Clustering slides
- The idea of finding patterns in the data
- The need for a similarity for the data
- The different features
- K-Means, K-Center and K-Meoids slides
- The NP-Problem of Clustering
- Using Cost functions for finding Clusters
- Using Approximation Algorithms for Clustering
- Beyond the metric space
- Hierarchical Clustering and Clustering for Large Data Sets slides
- Introduction
- The idea of nesting
- Bottom-Up Strategy
- Top-Down Strategy
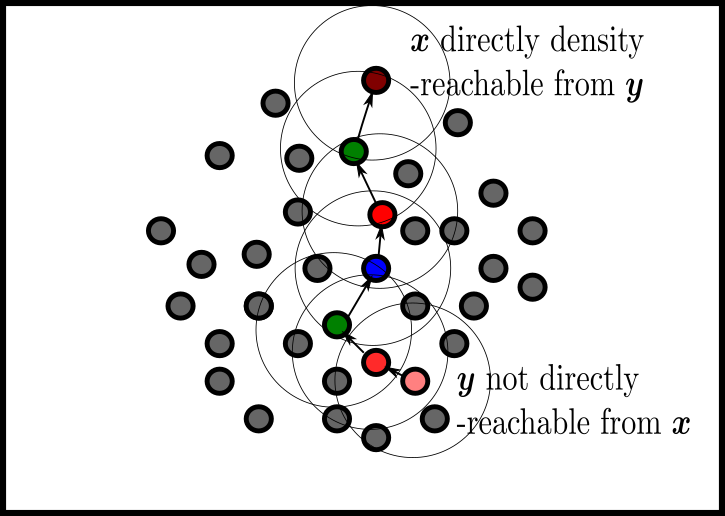
- Large Data Set Clustering: CURE and DBASE
- Cluster Validity slides
- An Introduction to cluster validity
- Associative Rules slides
- From the era of warehouses, finding frequent rules in databases
- Locality Sensitive Hashing slides
-
Hashing to find similar elements
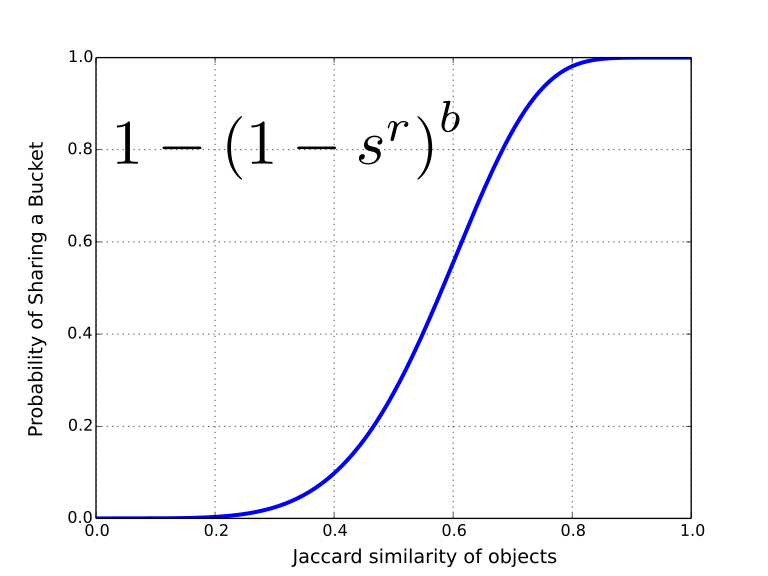
-
- Page Rank slides
- The Web as a Stochastic Matrix
- The Ranking as probabilistic vector
- The Power Method for finding the vector distribution
- Semi-supervised Learning slides
- The Basic of Semi-supervised Learning
- Using it on document labeling
Book Chapters on Machine Learning
Here the book chapters based on these slides
-
Linear Models
UNDER CONSTRUCTION