Introduction to Deep Learning
Here, we have some of my attempts to interpret the field of Deep Learning
- Introduction Slides
- Introduction
- The Neural Architecture
- Types of activation functions
- McCulloch-Pitts model
- Vanishing Gradient

- Neural Networks as graphs
- Examples
- Architectures
- Design of neural networks
- Representing knowledge on a Neural Network
- Learning Slides
- Introduction
- Error correcting learning
- Memory based Learning
- Hebbian Learning
- Competitive Learning
- Boltzmann Learning
- Perceptron Slides
- History and the beginning as PDE
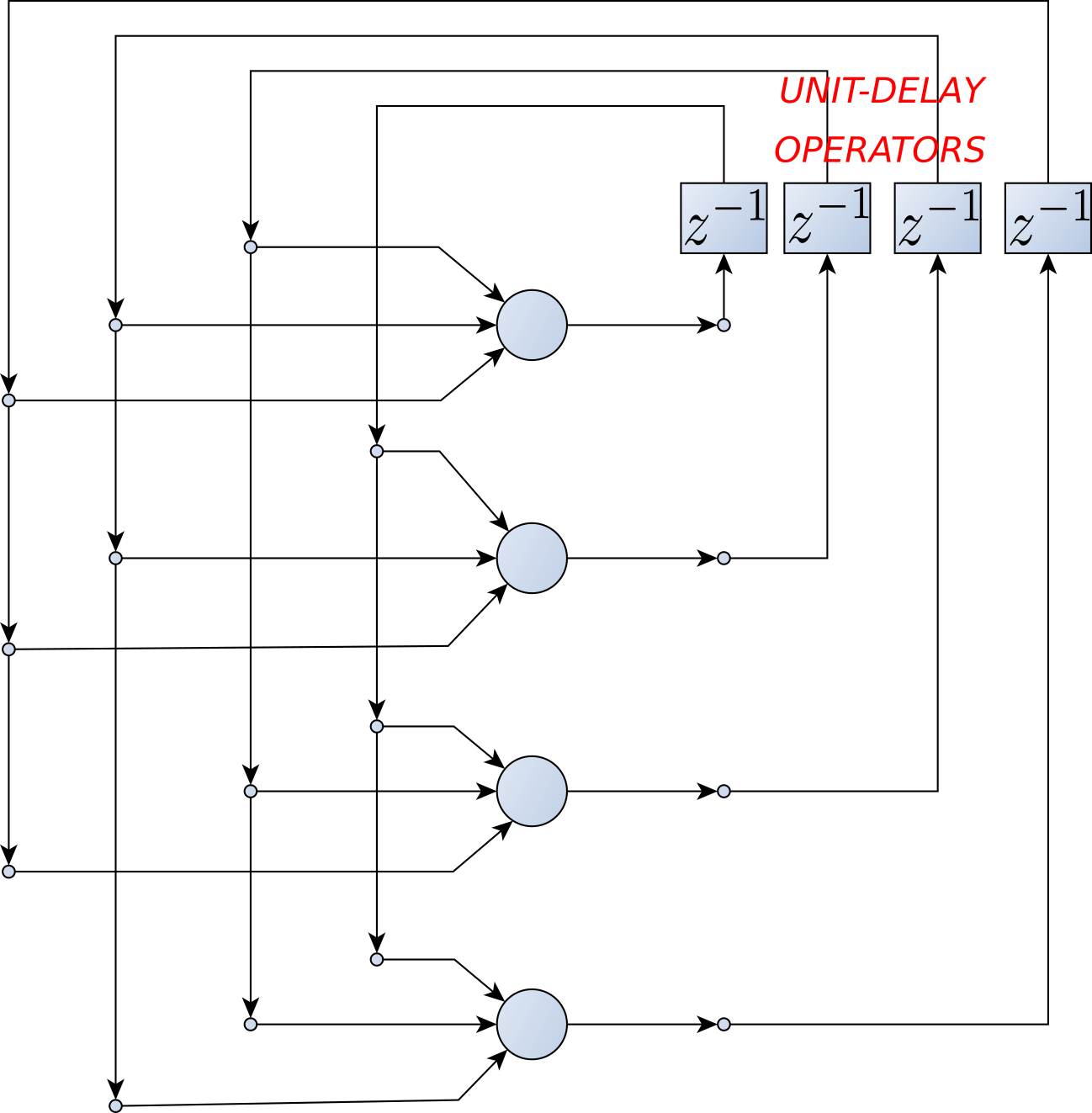
- Adaptive Filtering
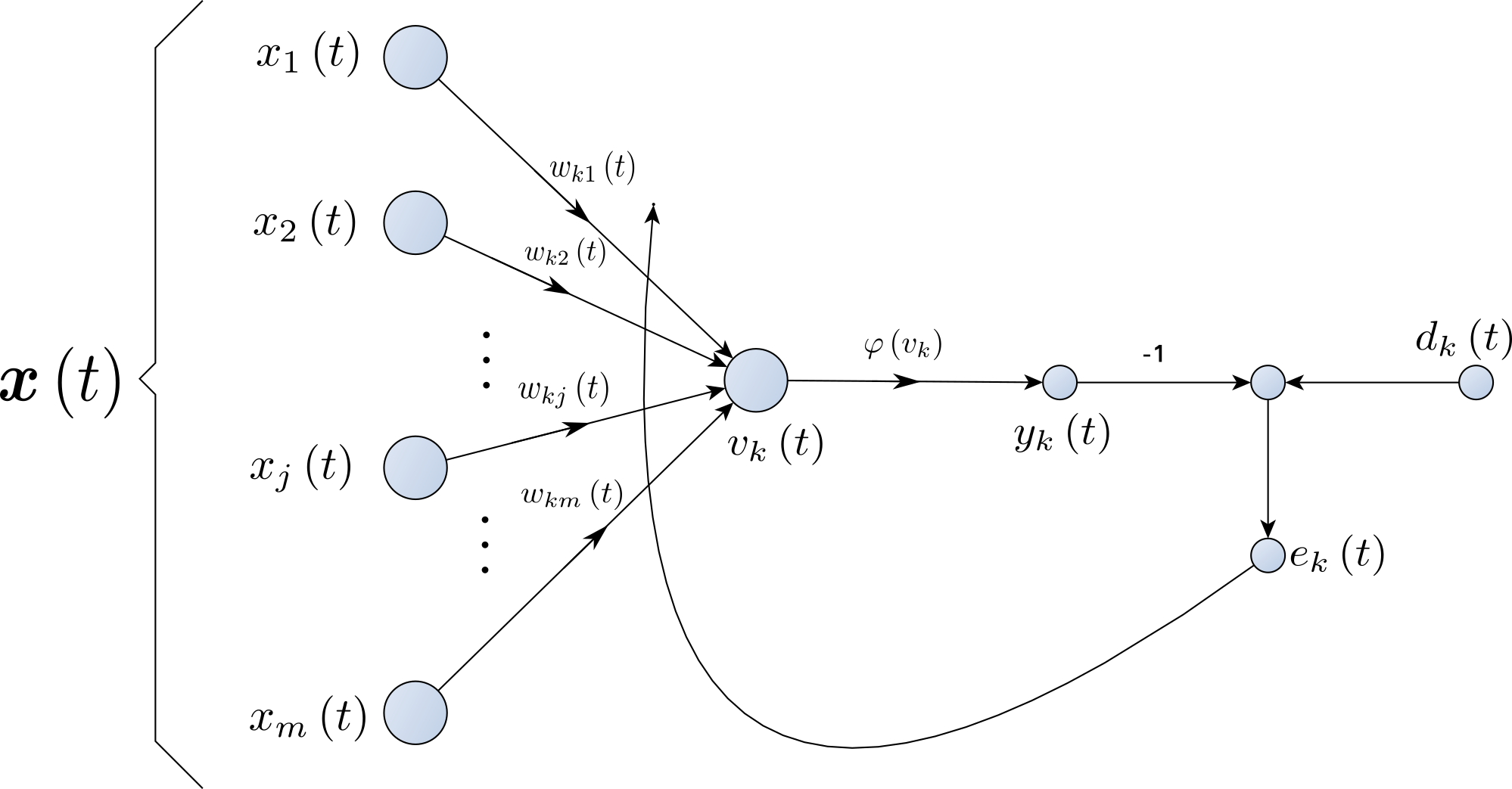
- Rosenblatt’s algorithm
- Multilayer Perceptron Slides
- Solving the XOR problem
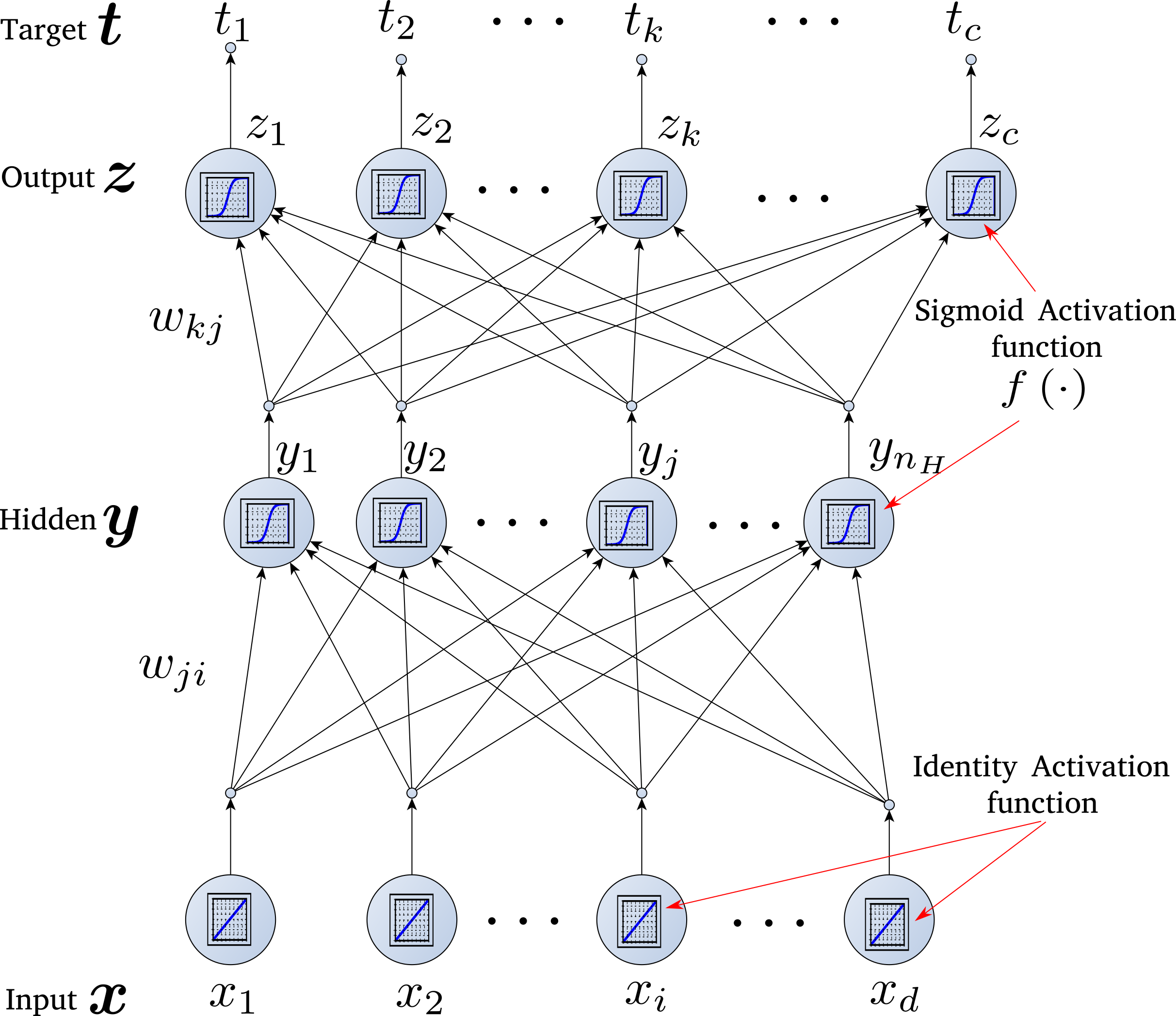
- The basic architecture
- Backpropagation
- Matrix form of the backpropagation
- The Universal Approximation Theorem
- Deep Forward Networks Slides
- The problem with shallow architectures - lack of expressiveness
- From simple features to complex ones
- Component of Deep Forward Architectures
- The Problems with the Gradient in Deeper Architectures
- RELU a possible solution
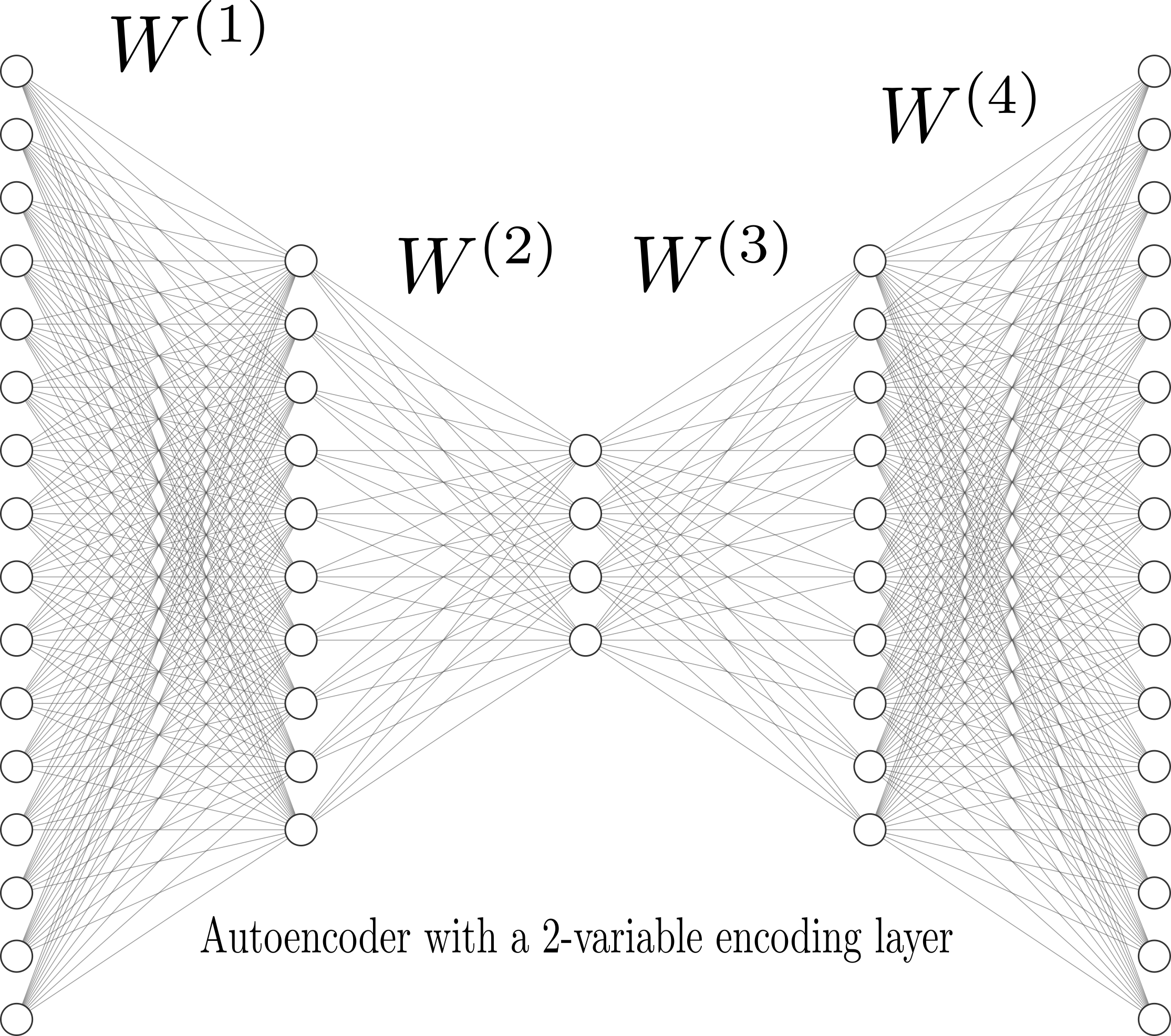
- Examples of Deep Architectures: Generative, Residual, Autoencoders, Boltzmann Machines, etc
- The idea of Back-propagation and Automatic Differentiation Slides
- Derivation of Network Functions
- Function Composition
- The Rule Chain AKA Backpropagation
- Advantages of Automatic Differentiation
- Forward and Reverse Method
- Proving the Reverse Method
- Basic Implementation of Automatic Differentiation
- Stochastic Gradient Descent Slides
- Review Gradient Descent
- The problem with Large Data sets
- Convergence Rate
- Accelerate the Gradient Descent: Nesterov
- Robbins-Monro idea
- SGB vs BGD
- The Minbatch
- Least-Mean Squares Adaptive
- AdaGrad
- ADAM
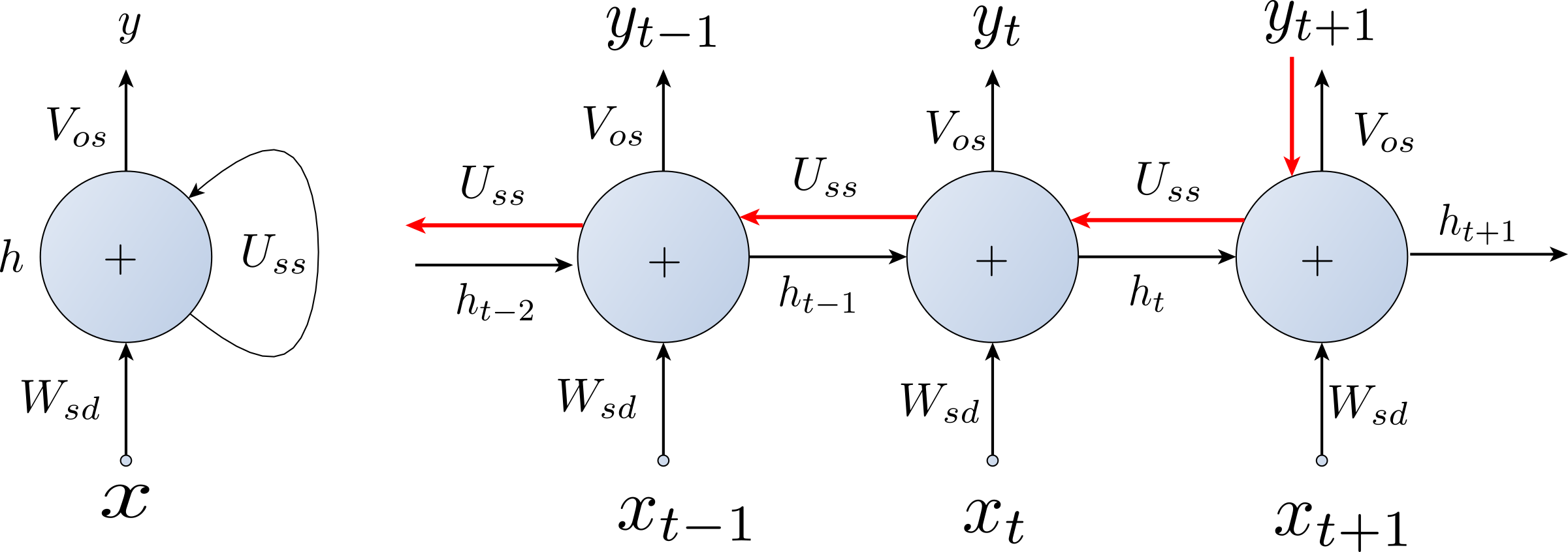
- Introduction to Recurrent Neural Networks Slides
- Vanilla RNN
- The Training Problem
- Backpropagation Though Time (BPTT)
- Dealing with the problem LSTM and GRU
- Can we avoid the BPTT?
- Regularization in Deep Neural Networks Slides
- Bias-Variance Dilemma
- The problem of overfitting
- Methods of regularization in Deep Neural Networks
- Dropout
- Random Dropout Probability
- Batch Normalization
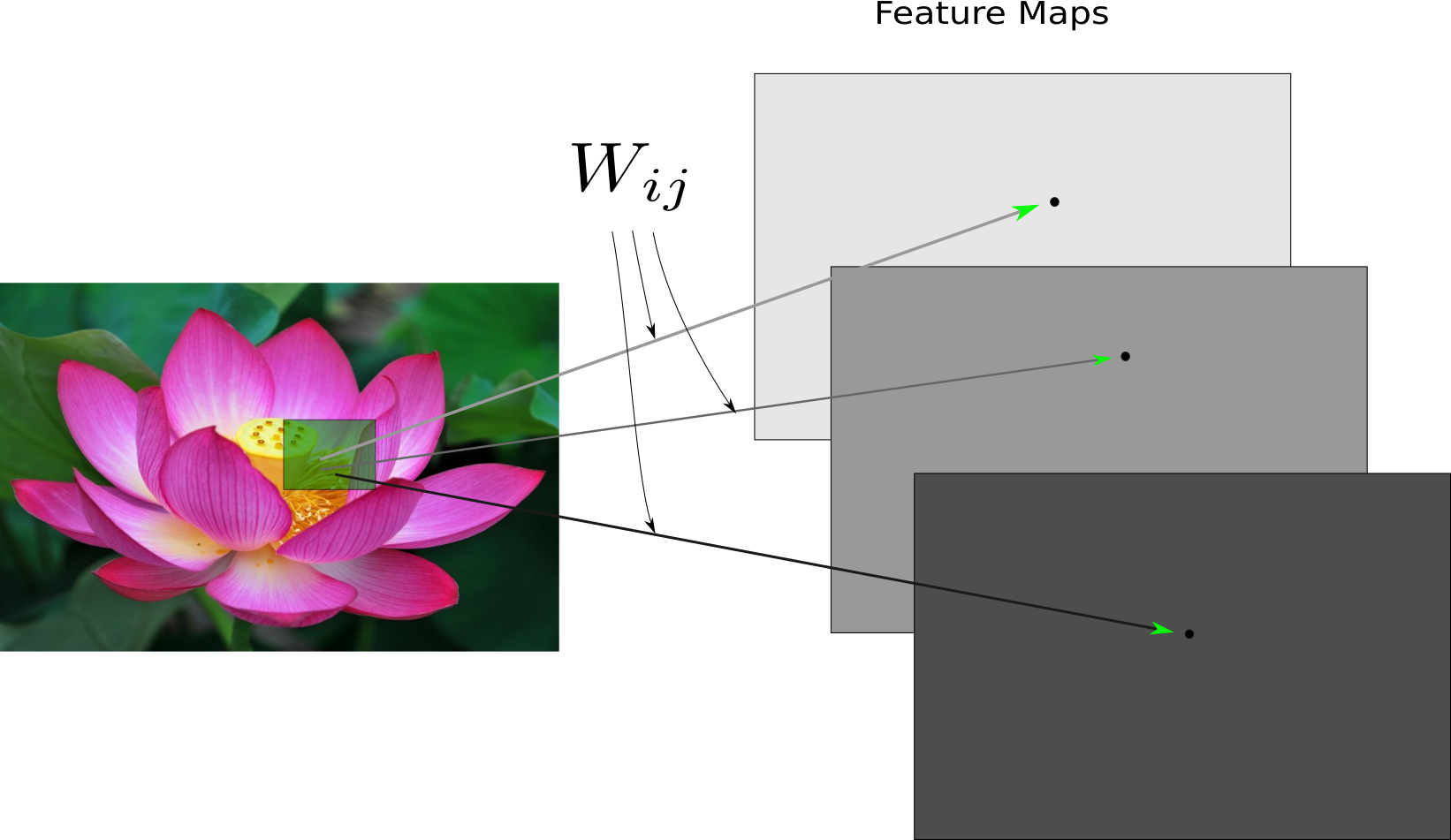
- Convolutional Networks Slides
- The problem of the translation on images
- The need of locality
- The Convolutional Operator
- Convolutional Networks
- Layers in Convolutional Networks
- An Example
- Loss Functions Slides
- The Loss Functions
- Hilbert Spaces
- Reproducibility
- The Quadratic Loss
- The problem with it
- The Logistic and 0-1 Loss
- Alternatives
- Beyond Convex Loss Functions
- Conclusions
-
Boltzmann Machines
\[\] -
Autoencoders
\[\] -
Evaluation of Deep Neural Networks
\[\] -
Generative Adversarial Networks
\[\] -
Transfer Learning
\[\] -
Deep Residual Networks
\[\] -
Second Order Methods
\[\] -
Partial Differential Equations in Deep Learning
\[\]
UNDER CONSTRUCTION